obelisk.hatenablog.com
前回のエントリで Ruby で実装してみた L-system を使って、実際に再帰曲線を描いてみます。Gem 'kaki-lsystem' が必要です。
C曲線。
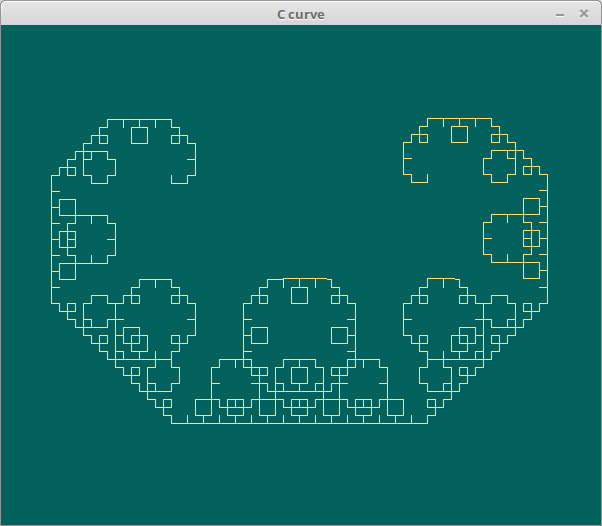
コード。
require 'kaki/lsystem' l = Lsystem.new(600, 500, "C curve") l.move(-130, 100) l.prologue do clear(color(0x2b5, 0x60ff, 0x5d89)) color(0xfc9e, 0xe0aa, 0x7ac7) end l.set("-") {left(45)} l.set("+") {right(45)} l.set("F") {forward(8)} l.init("F") l.rule("F", "+F--F+") l.draw(10)
以下、require 'kaki/lsystem' は書きません。
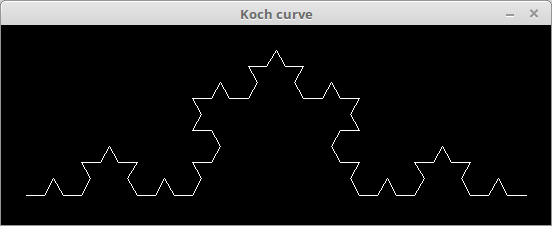
コッホ・アイランド。
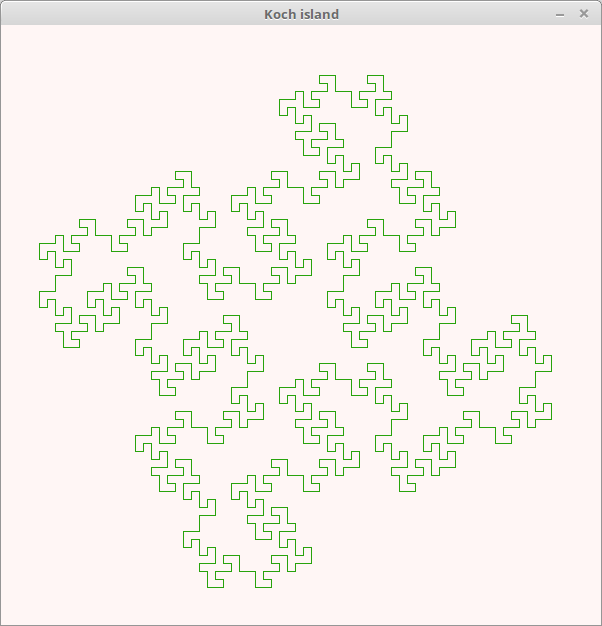
コード。
l = Lsystem.new(600, 600, "Koch island") l.move(-150, -150) l.prologue do clear(color(0xffff, 0xf600, 0xf540)) color(0x28a5, 0xa3c8, 0xca7) end l.set("-") {left(90)} l.set("+") {right(90)} l.set("F") {forward(8)} l.init("F-F-F-F") l.rule("F", "F+FF-FF-F-F+F+FF-F-F+F+FF+FF-F") l.draw(2)
ペンローズ・タイル。
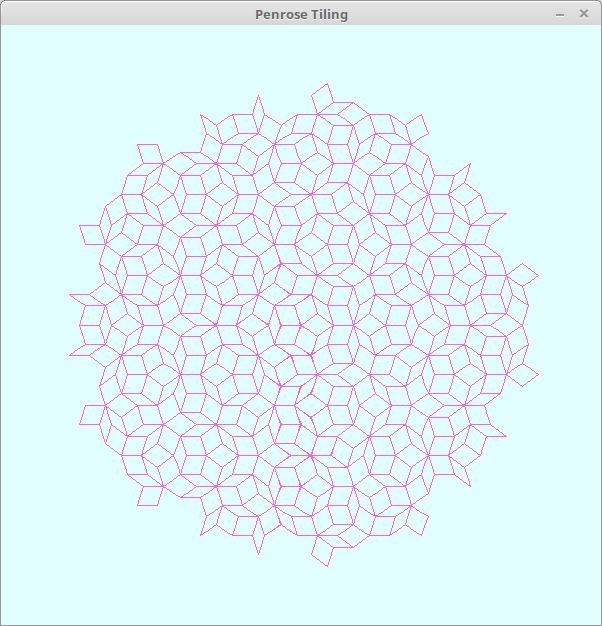
コード。
l = Lsystem.new(600, 600, "Penrose Tiling") l.prologue do clear(color(0xe013, 0xfee3, 0xfee3)) color(0xffff, 0x5feb, 0xe51f) end l.set("-") {left(36)} l.set("+") {right(36)} walk = proc {forward(10)} l.set("M", &walk) l.set("N", &walk) l.set("O", &walk) l.set("P", &walk) l.set("A", &walk) l.init("[N]++[N]++[N]++[N]++[N]") l.rule("M", "OA++PA----NA[-OA----MA]++") l.rule("N", "+OA--PA[---MA--NA]+") l.rule("O", "-MA++NA[+++OA++PA]-") l.rule("P", "--OA++++MA[+PA++++NA]--NA") l.rule("A", "") l.draw(5)
Sierpinski arrowhead。続けると「シェルピンスキーのギャスケット」になります。
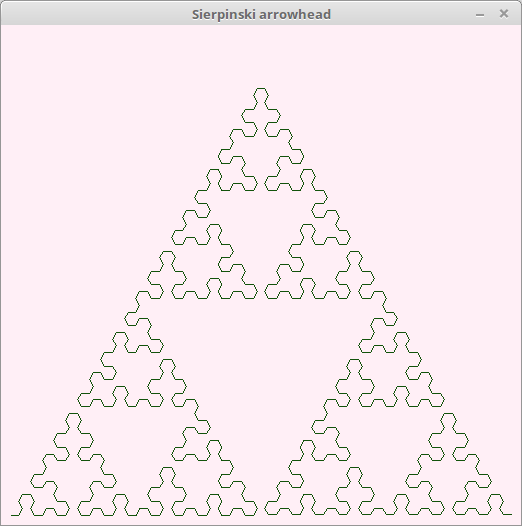
コード。
n = 6 length = n.zero? ? 500 : 500.0 / 2 ** n l = Lsystem.new(520, 500, "Sierpinski arrowhead") l.move(-250, -240) l.prologue do clear(color(0xffff, 0xef5b, 0xf677)) color(0x12de, 0x5320, 0xb4a) end l.set("-") {left(60)} l.set("+") {right(60)} l.set("L") {} l.set("R") {} l.set("F") {forward(length)} l.init("LF") l.rule("L", "-RF+LF+RF-") l.rule("R", "+LF-RF-LF+") l.rule("F", "") l.draw(n)

コード。
l = Lsystem.new(500, 500) l.move(50, -230) l.prologue do clear(color(0xd467, 0xfbab, 0xd0c7)) color(0xe713, 0x5742, 0xff23) end l.set("-") {left(90)} l.set("+") {right(90)} l.set("F") {forward(10)} l.init("F-F-F-F") l.rule("F", "FF-F-F-F-F-F+F") l.draw(3)
草っぽいの。

コード。
l = Lsystem.new(500, 500) l.move(-150, -240) l.prologue do clear(color(0xf7d3, 0xffff, 0xc99b)) color(0x30e3, 0x8636, 0x10d2) end l.dir = Vector[0, 1] l.set("-") {left(10)} l.set("+") {right(15)} l.set("F") {forward(13)} l.set("X") {} l.set("Z") {} l.init("X") l.rule("F", "FX[FX[+XF]]") l.rule("X", "FF[+XZ++X-F[+ZX]][-X++F-X]") l.rule("Z", "[+F-X-F][++ZX]") l.draw(4)
ペアノ・ゴスペル曲線。
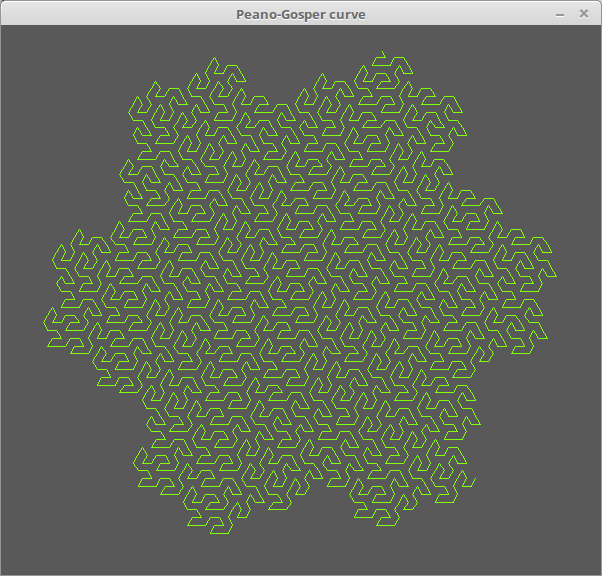
コード。
l = Lsystem.new(600, 550, "Peano-Gosper curve") l.move(80, 250) l.prologue do clear(color(0x5968, 0x5968, 0x5968)) color(0x8024, 0xffff, 0x653) end l.set("-") {left(60)} l.set("+") {right(60)} l.set("F") {forward(9)} l.set("X") {} l.set("Y") {} l.init("X") l.rule("X", "X+YF++YF-FX--FXFX-YF+") l.rule("Y", "-FX+YFYF++YF+FX--FX-Y") l.draw(4)
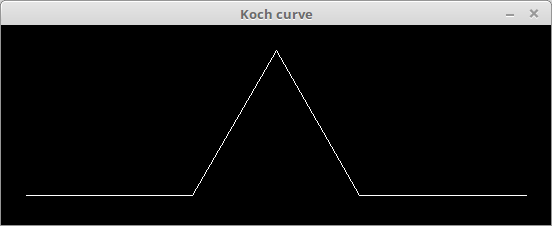
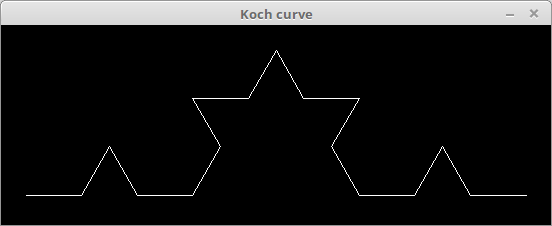





")

