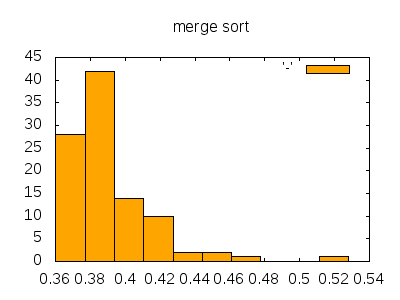
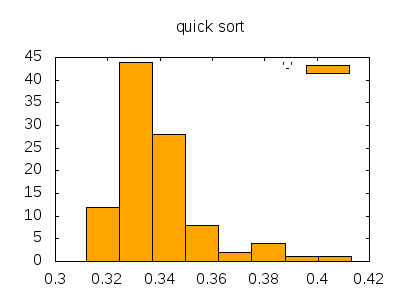
バケットソートはバケツソート、ビンソート、計数ソート(後記:計数ソートとバケットソートはちがう)などとも言います。非常に高速ですが、ソートされる対象は 0以上の整数値(またはそれに変換できるもの)であり、その最大値が大きくなるとメモリをバカ食いします。また、値に重複がない場合はここにあるように Ruby では
class Array def bucket_sort inject([]) {|mem, var| mem[var] = var; mem}.compact end end
と驚異的にシンプルに書けますが、値の重複を許すとそんなに簡単ではないようです。
バケットソートについては小飼弾さんのブログ記事が啓蒙的です。
参考書の手続きを Ruby でコーディングしてみました。値が重複する場合も対応しています。
class Array def counting_sort #Integer{self[]} -> Integer{m, equal[], result} m = max + 1 equal = Array.new(m, 0) size.times {|i| equal[self[i]] += 1} equal[-1] = 0 (m - 1).times {|i| equal[i] += equal[i - 1]} result = Array.new(size) size.times do |i| result[equal[self[i] - 1]] = self[i] equal[self[i] - 1] += 1 end result end end
やっていることは、値の最大値 + 1 を m として、まず大きさ m の配列 equal を作り、値 a の(重複する)要素の個数を equal[a] に入れます。つまり、ソートすべき配列に 4の値が 3個あれば、equal[4] = 3 とするということです。
次に、値 a より小さいすべての要素の個数を equal[a - 1] に入れます。
最後に並べ直します。ソートすべき配列と同じ大きさの配列 result を作り、ソートすべき配列の i 番目の値 a が result[equal[a - 1]] に入ります。重複したものが重ねて入らないように equal[a - 1] をインクリメントします。これをすべての i について繰り返すと、result に答えが入っています。
バケットソート計数ソートは上を見てわかるとおり、「値の比較」というものをまったくやっていません。それが高速になる理由です。
※追記 どうやらこのソートはバケットソートではなく、計数ソートというべきのようです。日本語版 Wikipedia は記述がまちがっているようだ。計数ソートとバケットソートは同じではないらしい。計数ソートは「安定的な」ソートです。つまり重複部分で、オブジェクトなど、付随するデータの順序を変えません。

- 作者: トーマス・H・コルメン,長尾高弘
- 出版社/メーカー: 日経BP社
- 発売日: 2016/03/11
- メディア: 単行本
- この商品を含むブログ (5件) を見る
※追記
ぐぐっていたらもっとシンプルな実装を見つけました。多少好みの書き方に直して下に記しておきます。(後記:これはバケットソートなんでしょうか、よくわかりません。)
class Array def bucket_sort m = max + 1 equal = Array.new(m, 0) size.times {|i| equal[self[i]] += 1} result = [] m.times do |i| equal[i].times {result << i} end result end end
後半でループがネストしているのでサイズが大きくなると不利かなと思いましたが、ベンチマークしてみると、サイズが小さくても大きくてもこちらの方が若干速いようです。何といってもシンプルなので、こちらの方がいいですね。
ただひとつ気になるのは、こちらの実装だとサテライトデータ(ソートに付随するデータ)が扱えないのではないでしょうか(つまり、「安定的な」ソートではない)。最初の実装はサテライトデータを扱うことが可能です。