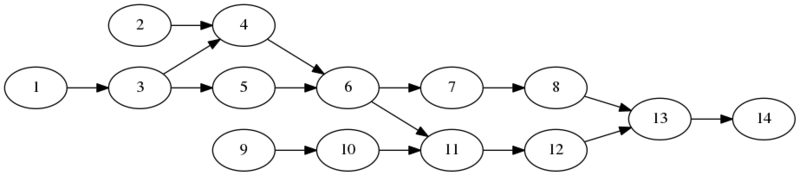
上の閉路なし有向グラフ(DAG)のように、辺に「重み」が付いている場合において、最短経路を求めてみます。手続きは
入力:
- G: n 個の頂点の集合 V と m 本の有向辺の集合 E を含む閉路なし有向グラフ。
- s: V の始点。
出力:
Ruby でコーディングしてみました。メソッドは [@shortest, @pred] を返します。@pred を見ると最短経路がわかります。
dag_shortest_paths.rb
require './topological_sort' class Hash def dag_shortest_paths(s) #%dis = Rational or Integer or Float, %node = Object #Hash{self[%node]: (Hash[%node]: %dis)}, %node{s} -> #Hash{h[%node]: Array[%node], @shortest[%node]: %dis, @pred[%node]: %node} #%node{l[]} h = map {|x| [x[0], x[1].keys]}.to_h l = h.topological_sort @shortest = h.keys.map {|k| [k, Float::INFINITY]}.to_h @pred = {} @shortest[s] = 0 l.each do |u| h[u].each {|v| relax(u, v)} end [@shortest, @pred] end def relax(u, v) #%node{u, v} --> %dis{a} if (a = @shortest[u] + self[u][v]) < @shortest[v] @shortest[v] = a @pred[v] = u end end private :relax end if __FILE__ == $0 g = {s: {t: 2, x: 6}, t: {x: 7, y: 4}, x: {y: -1, z: 1}, y: {z: -2}, z: {}} p g.dag_shortest_paths(:s) end #=>[{:s=>0, :t=>2, :x=>6, :y=>5, :z=>3}, {t=>:s, :x=>:s, :y=>:x, :z=>:y}]
topological_sort.rb は前エントリのコードです。ハッシュを使うとき、to_h 便利ですね。
念のため、返り値 @pred から最短経路を順に配列に入れて返すメソッドを書いておきます。
class Hash def get_order(a) #Hash{self[%node]: %node}, %node or nil{a} -> %node{order[]} order = [] while a order.unshift(a) a = self[a] end order end end pred = {:t=>:s, :x=>:s, :y=>:x, :z=>:y} p pred.get_order(:z) #=>[:s, :x, :y, :z]

- 作者: トーマス・H・コルメン,長尾高弘
- 出版社/メーカー: 日経BP社
- 発売日: 2016/03/11
- メディア: 単行本
- この商品を含むブログ (5件) を見る
追記
Hash クラスへのモンキーパッチでないように書き換えました。(2019/5/6)
def dag_shortest_paths(g, start) h = g.map {|x| [x[0], x[1].keys]}.to_h l = topological_sort(h) shortest = h.keys.map {|k| [k, Float::INFINITY]}.to_h pred = {} shortest[start] = 0 l.each do |u| h[u].each do |v| if (a = shortest[u] + g[u][v]) < shortest[v] shortest[v] = a pred[v] = u end end end [shortest, pred] end def topological_sort(h) in_degree = Hash.new(0) ans = [] h.each_value do |v| v.each {|x| in_degree[x] += 1} end nxt = h.keys.select {|x| in_degree[x].zero?} until nxt.size.zero? u = nxt.shift ans << u h[u].each do |v| in_degree[v] -= 1 nxt << v if in_degree[v].zero? end end raise "グラフに閉路があります。" if in_degree.values.find {|x| not x.zero?} ans end if __FILE__ == $0 g = {s: {t: 2, x: 6}, t: {x: 7, y: 4}, x: {y: -1, z: 1}, y: {z: -2}, z: {}} p dag_shortest_paths(g, :s) end #=>[{:s=>0, :t=>2, :x=>6, :y=>5, :z=>3}, {t=>:s, :x=>:s, :y=>:x, :z=>:y}]